Atharva InamdarWarehouse or Lake House? What to build and what actually matters?A bit of a ramble of thoughts realising the trends of data engineering5 min read·May 4, 2024----
Atharva InamdarUnderstanding `Optional` and `Nullable` propertiesEffect of optional vs nullable properties on data quality3 min read·Sep 4, 2022----
Atharva InamdarTwo skills I value and look forSoft skills that are most valuable in engineering4 min read·Jul 27, 2022----
Atharva InamdarinAnalytics VidhyaEnabling testing and local development with Spark and AWSIntegrating Spark with LocalStack·3 min read·Oct 9, 2021----
Atharva InamdarDIY Baby Monitor with Raspberry PiStreaming video with Raspberry Pi4 min read·Feb 9, 2021----
Atharva InamdarinTowards Data ScienceUnderstanding Apache ParquetUnderstand why Parquet should be used for warehouse/lake storage4 min read·Sep 26, 2020--1--1
Atharva InamdarinAnalytics VidhyaBBC micro:bit as a Wireless SensorUsing the micro:bit as a wireless transmitter for Analogue sensors3 min read·Sep 4, 2020----
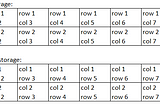
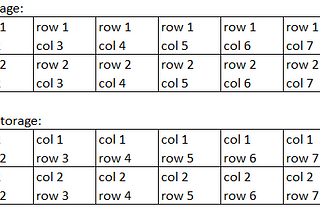
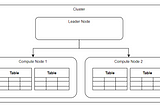
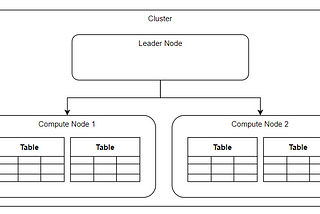
Atharva InamdarinTowards Data ScienceAmazon Redshift ArchitectureUnderstanding the foundations of Redshift·4 min read·Aug 16, 2020----
Atharva InamdarIntroduction to AWS RedshiftWhat is AWS Redshift and why is it different?2 min read·Aug 9, 2020----